Nearly every week for the past two years we've seen an agency come out and announce its new proprietary AI platform designed to futureproof them from the tide of change washing into the industry.
And look - the instinct to experiment, to build, to figure out what this technology can do? That's a good - no, great - instinct! We should all be playing with this stuff. But there's a meaningful difference between experimentation and an over six-figure headline investment that claims to have bottled the magic of what an agency does into a piece of software.
The first one I'd encourage wholeheartedly. The second one deserves a harder look.
The rationale driving this is legitimate - there’s a sense AI is going to eat your lunch, so you’d better get there first to have some kind of defensible moat to hide behind. We’ve seen many agencies disappear (DDB, Chep, anyone?) - and the narrative is always the same, they failed to adapt to the new world order.
That’s one of the most eviscerating things someone in an industry which prides itself of being on the vanguard of culture, creativity and innovation can hear. No-one wants to get left behind.
Generative AI technology is genuinely transformative and it’s already changing the equation for much of the industry. So experimenting with your own tools, building things to learn, figuring out where AI can genuinely improve your process - all of that makes complete sense.
The question worth sitting with now is a different one: do you actually want to be in the business of building and selling technology? Because that's a different business entirely.
Agencies are not technology companies and for a long time, that's been their advantage, not their limitation.
Think about what the advertising industry has actually sold for the past hundred-odd years: people and process. People who understand culture, who can make a stranger feel something in thirty seconds, who have the taste and judgement to know when an idea is sharp versus when it just looks sharp.
I’ve come from an agency background, I cut my teeth in media and creative shops and know how they work incredibly well. And yes, I'm an agency person who ended up building an AI platform, so I understand the impulse better than most.
But I also understand the challenges and what it actually takes - all things I didn’t comprehend fully when I started this journey. Creating something that’s not just a minimum viable product you can play about with yourself is costly - both in terms of time and cold, hard cash.
We started Springboards when the generative AI space was only just burgeoning and the benchmark was relatively low. That's not the environment agencies are walking into today.
Every agency has their proprietary framework, their unique methodology, their special sauce - a bit of theatre around a sensible process.
There's nothing wrong with that but the stakes are different now. When a holding company announces it's automating the creative process with a billion-dollar AI platform, it's not just smoke and mirrors - it's actively adding fuel to the argument that the work your people do can be replicated by a machine.
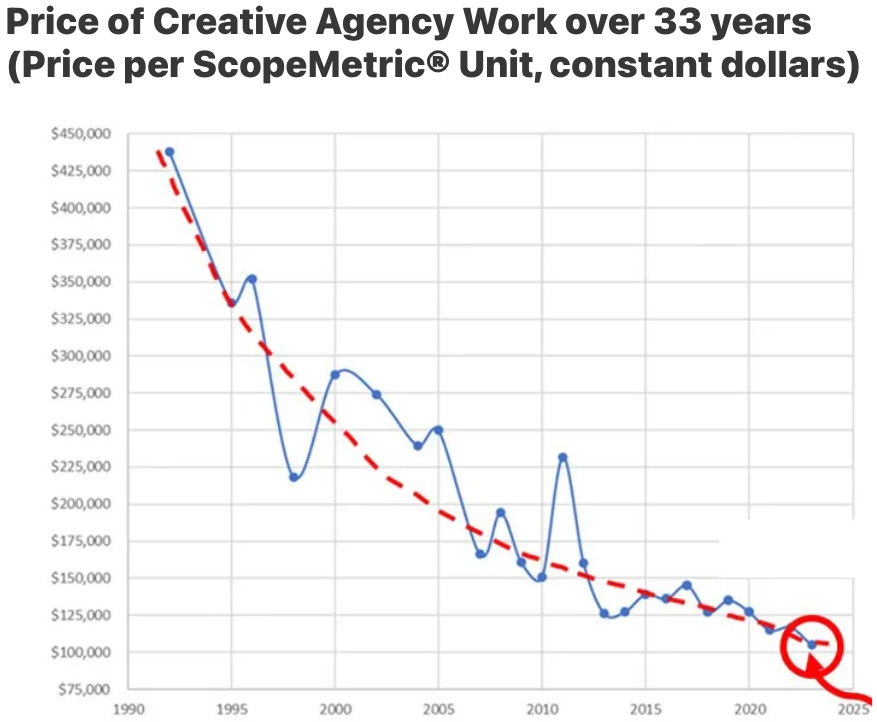
The reality of agencies building their own tools often comes down to margins. Agency margins have been declining for a decade or more. This chart from Michael Farmer’s C-Suite Blues is stark, visual proof of this worrying trend - here, we can see the steep, gradual decline in how agencies price creative work:
How agencies price creative work. Source: Farmer & Company Client Data.
All of this is to say that the cash position that might justify a long-term technology moonshot - the kind of burn-now-to-win-later strategy that powers Silicon Valley - simply isn't there.
VCs fund technology companies with the explicit expectation of losing money on the path to dominance. The reality is that for every one or two VC-backed startups that turn into Canva, there are far more that fail.
It's an incredibly risky business model. It works when you have a runway but show me an agency, particularly a publicly listed HoldCo, in that kind of position that has the permission and expectation to fail trying.
There’s also the fact that technology is never just an initial outlay. This is the part that gets underestimated - the moment you build a proprietary AI platform and put it into the world, you're not done - you're only at the beginning of a very long, very bumpy journey.
You're now competing on technology, which means you have to keep advancing it, keep staffing it, keep making it better against competitors who are funded specifically and lavishly to do exactly that and burning millions or billions of dollars each month in the process.
There's also a talent dimension that doesn't get talked about enough. A lot of what AI now handles - competitive audits, first-pass research, early-stage analysis - used to be where junior people learned their craft.
The grunt work, as unglamorous as it sounds, was a training ground. The place where someone figured out what a good brief looks like, what a weak insight feels like and what separates a sharp thought from a predictable one. When you remove that, you compress the development pipeline for the people who eventually make the brilliant work.
Talent development has always been an imperfect science for agencies, and doing less of it, at the same time as redirecting investment away from people entirely, is a compounding problem worth taking seriously.
The question isn't whether to use AI or even whether to build things with it - it absolutely should be part of how you work. It's about being honest about what you're actually in the business of selling.
If you genuinely have the talent, proprietary knowledge and the capital to build something scalable that is going to be better than something that can be repurposed off the shelf, then go for it. The upside potential is enormous.
But if your business was built on human ingenuity - and the evidence of the past hundred years suggests it was - then the more interesting question might be: what would happen if you put that investment into your people instead? Into training programs that actually develop craft and creative judgement or into the processes that make your way of thinking genuinely distinctive?
Because the uncomfortable truth about AI and creativity is it’s generally not good at creating great work. That might sound odd coming from an AI company - but it's exactly why we built Springboards.ai the way we did, with people at the centre of every process and a healthy scepticism toward fully agentic systems that remove human judgement from the equation.
There's certainly something a little upside down about an AI company being the ones flying the flag for human creativity while some of the biggest agency networks in the world seem to be moving in the opposite direction.
The thing that makes an idea land isn't its coherence or its probability, it is the unexpectedness. No-one expected meerkats to sell insurance (Compare the Market) or a passive aggressive owl to encourage second-language learning (Duolingo).
But these were stellar examples of creativity which worked, cut through and grabbed people by the feels and moved markets and built businesses. It is what clients come to agencies for.
That requires human judgement which can only come through lived experience, gut feeling and a lot of counterintuitive thinking to make it work.
Technology has been, is and will increasingly be an important and useful part of your process - a smart, efficiency-generating, possibility-expanding part. But for agencies, the future isn’t about who can produce something faster or more efficiently, it’s about selling the wet matter between your people’s ears which no machine can replicate in a meaningful way.
In case you hadn’t realised already, your clients were buying your people. They still are. Don’t optimise them out.
Want to explore this further? Book a call with the team today.
James is one of the most influential thinkers in Marketing today and for those who weren’t able to make the session - he was every bit the “James Hurman” you’ve heard about, sharing his gift for being able to simplify the complex.
“Future Demand” is not only the title of his latest book but also the lens through which he argues we need to fundamentally rethink how marketing works. The name is straightforward, but what sits behind it is thirty years of marketing science, distilled into something you can act on immediately.
Hurman systematically - and politely we might add, exposed one of the most stubborn arguments in our industry for what it actually is. An endless and sadly unnecessary tug of war. The rational and the emotional or as the industry tends to express them - performance and brand. We have spent decades treating these as opposing forces, as if choosing one means sacrificing the other.
James's argument is that this tension was never real. It was merely a symptom of asking one piece of communication to do two fundamentally incompatible jobs. The moment you separate those jobs i.e. convert current demand over here, create future demand over there, the tension collapses. Rational and emotional are not in conflict. They are just answers to different questions. The brief that needs to close a sale today should be rational. The brief that needs to plant something in the mind of a buyer who won't show up for six months should be emotional. Both are right. Neither is wrong. They were just never meant to be the same brief.
If you get nothing else from this Spark Sessions masterclass, the evidence and framing Hurman uses to make this argument is worthwhile. Most marketers know this intuitively, but the ability to level this argument in a compelling and simple way is truly powerful.
Today's customers are reached by performance marketing. People who are in the market for your product or service now.
Tomorrow's customers are being reached through brand marketing. People who will need your product or service in the future.
If you take this framing a step further though into implications for your craft, the session can also empower your performance work to be just that - simple and direct, it can also give your brand work greater permission to be genuinely creative. The second layer to this session - which he weaves throughout his evidence, is the clear acknowledgement in how the laws of demand creation vs demand capture differ.
We all know this as Marketers, but no matter how drastic a shift in the way we interface with technology, the way we make decisions hasn’t changed that much at an emotional level. That change takes a long time. It means that although new category entry points and media touchpoints might exist in an AI-enabled world, brands are built with the same basic ingredients. How and when you use these ingredients has changed somewhat, but the human part - the creative part - that’s still the point of difference.
That very human Creativity is something we believe is at the core of all marketing considered to be valuable today. That’s the part we get really riled up about! Given how steeped our industry and space is in technology and what’s new, it’s important we’re protective of what actually makes marketing the most valuable. Data-rich addressable channels and finely tuned conversion engines are all happy by products of a really bloody good creative idea. So - if you take anything else away from Hurman’s work, perhaps some encouragement in that the biggest driver of brand value remains purely biological.
If you extrapolate Hurman’s lens to how we see people deploying AI in Marketing…the Strategies relevant in demand capture just aren’t relevant in demand creation. So, why would you use the same tool to analyse your search data to develop a creative concept for your brand TVC? It’s a crude analogy but specialism matters here, which is a big part of why Springboards exists.
Most AI models are built to converge, to find you the most polished, probable and expected answer. That’s a feature if you’re trying to find out what ad performed best in your Search Campaign, if you’re a creative or a strategist trying to build an idea for future demand - that’s a bug. We built a platform designed to help you expand your range of thinking, to help teams explore more possibilities without replacing human judgement or craft. The unexpected needs to be intentionally pursued in an AI-enabled world, and we’re passionate about creating and protecting those environments.
Want access to masterclasses like James Hurman?
Unlock Springboards + monthly Spark Sessions for as little as $1 a day.
Join us June 24 @ 9:00 EDT with Mark Pollard for his "How the world thinks" masterclass.
Having spent years travelling, talking to people, collecting ideas from places most strategists never look - this is a tour of that thinking. Sign up today.
For those who have followed Zoe Scaman on LinkedIn, she stands out not only for her intelligence, but her refreshing honesty. She exudes someone who has spent a career refining who she is and how she thinks. In this session, she showed us her working.
The topic of her talk was “The Whetstone” - the name perfectly encapsulates a competitive advantage that starts with mapping out our own practice. Not easy, but we left feeling it’s a rewarding journey to undertake. As she says, a sharper blade cuts further.
And that is what choosing the Whetstone path is really about. It’s a decision to use AI not to do the work for you, but to sharpen your mind. While many people are still using AI for efficiency, Zoe offered the perspective of levelling up. She uses AI to map her unique thinking processes and continues to sharpen as she sharpens. The journey of self-discovery that it takes to get there involves extracting tacit knowledge you’ve built up over a lifetime, but often can’t articulate.
Over the course of our careers, many of us have learned how to become an arbiter of our own taste. How to form our own distinct views. How to define and sharpen our personal brand. Our creative industry isn’t one you can simply learn out of a textbook. It has always been about tapping into the unique strengths and experiences that give us our own way of seeing the world and the challenges in front of us.
Zoe’s map of tacit knowledge will look different to each of ours. It was fascinating to hear how she holds a mirror up to the different experiences that make her think the way she does today. It’s not something you or I can simply copy and paste. That is the beauty of the human, unpredictable paths we have all taken.
Zoe’s advice is simple. Go on a walk. Get introspective. Map out the things that make your thinking different. Then use AI to help you extract the things you can’t put into words. Ask it to make you react and give your opinion. Do the hard work to put those indescribable strengths into codified thinking that you can continue to shape. It is not a one and done exercise. Our daily experiences will continue to change our viewpoint.
When you bring your own map of tacit knowledge into a session, you start to use AI in ways that do not feel like a path to average. It was a breath of fresh air to think that we can continue to defend the quirks of our humanity that lead to unexpected, creative thinking.
Most surface-level AI output isn’t wrong. It’s just dull. It will get you through the day, but it won’t cut through. Zoe’s point is that sharpness is still a choice. You either use these tools to smooth your edges, or you use them to find them and refine them. In choosing the Whetstone path, you’re protecting the most important creative differentiator you have, yourself.
Want access to masterclasses like Zoe Scaman’s?
Unlock Springboards + monthly Spark Sessions for as little as $1 a day.
Join us May 28 @ 8:00 NZST with James Hurman for his "Future Demand" masterclass uncovering why marketing to tomorrow’s customers will break your brand out of the performance trap.
James will reveal why so many brands have optimised themselves onto a growth plateau, and share the evidence-based way out. Drawing on decades of global research, he’ll show what brands can do to create profitable growth that scales.
This session proposes a new mental model for marketing, built on how markets really work, how humans really make decisions, and how advertising really creates sales. Sign up today.





.svg)
