World’s first LLM benchmark for creativity finds AI tools are more similar than you think
March 9, 2026
In the news
The 4As, IAA and more leading industry groups teamed up with Springboards to compare how top AI tools like ChatGPT, Gemini and Claude perform on creative tasks
New York, NY – October 21, 2025 – A comprehensive new study by Springboards, an AI platform inspiring creativity in advertising, found that popular AI tools like ChatGPT, Gemini, Claude and others perform much more similarly on creative tasks than many people think. Creativity Benchmark, conducted in collaboration with the 4As, ACA, APG, D&AD, IAA, IPA, and The One Club for Creativity, challenges the idea that there's a single "best" AI tool for creative work and shows agencies need more efficient ways to test AI tools for their specific needs.
Sixteen different AI systems – from OpenAI, Google, Anthropic, Meta, DeepSeek, Alibaba and others – were tested on real marketing challenges across 100 notable brands. Over 600 creative professionals from ad agencies, marketing teams, and strategy firms made over 11,000 comparisons to see which ones worked best. The biggest surprise? There was no clear winner. The differences between the "best" and "worst" AI tools were much smaller than expected.
"Everyone assumes some AI tools are way better than others for creative work," said Pip Bingemann, CEO and co-founder of Springboards. "But our tests showed the results were pretty close. Why? Because these models are machines designed to recognize patterns and give you the most probable answer—and 'probable' has never been called 'creative.' Keeping humans in the loop and optimizing for a wider range of varied ideas is crucial.”
The study looked at three types of creative challenges: finding surprising insights about consumers, creating big campaign ideas, and coming up with bold, attention-grabbing concepts.
Key Findings:
Different AI Tools Win at Different Tasks: No single AI system was best at everything. Some were better at strategic thinking, others at wild, creative ideas. This means agencies might want to use different tools for different jobs.
Variety of Ideas Matters Most: Some AI tools generated lots of different creative options for the same brief. Others kept suggesting similar ideas over and over. For real creative work, having many different options is just as important as having good ones.
AI Can't Judge Creative Work Well: When researchers had AI systems evaluate creative ideas, they gave very different scores than human experts. This means agencies can't rely on AI to pick the best creative concepts – they still need human judgment.
Standard Creativity Tests Don't Work for Marketing: Traditional creativity tests used in psychology don't predict which AI will be better at marketing-specific creative tasks. Brand work requires its own way of measuring creativity.
Creative Preferences Vary by Location: Interestingly, creative professionals in different countries preferred different AI tools, suggesting that cultural differences affect what people consider good creative work.
“LLMs aren’t a one-size-fits-all solution—they're general purpose tools that require human creativity to unlock breakthrough outcomes," said Jeremy Lockhorn, SVP, Creative Technologies & Innovation, 4As. "These findings suggest agencies and brands should continue to evaluate which models are best suited for creative work - and that a multi-model approach may well be the best path forward."
“This study highlights that creativity isn’t about which AI you use, it’s about how you use it,” remarked Tony Hale, CEO, Advertising Council Australia. “The results reinforce what we see across the industry: the human spark remains essential to transforming good ideas into great ones. For agencies, the real opportunity is learning how to collaborate with these systems to expand, not replace, creative thinking.”
Methodology
The study involved 678 advertising professionals of diverse backgrounds, who participated in blind A/B idea judgments, likened to a "Tinder for Ideas." The data, collected over four weeks starting June 10, 2025, comprised 11,012 human comparisons across various brands, prompts, and models. This was analyzed using Bradley-Terry modeling and cosine distance for diversity scoring.
The research used four different ways to test AI creativity:
Real Creative Professionals Made the Calls: Nearly 700 people working in advertising, marketing, and strategy compared AI-generated ideas side-by-side. They didn't know which AI created which idea, so they couldn't play favorites. The study covered ideas for 100 major brands across 12 different business categories.
Tested How Many Different Ideas AI Can Create: Researchers asked each AI system to create 10 different responses to the same creative brief, then measured how different those responses were from each other. Some AI tools generated very similar ideas every time, while others came up with lots of variety.
Checked If AI Can Judge Its Own Work: The team had three leading AI systems evaluate the same creative ideas that humans had already scored, to see if AI judges agreed with human experts. They didn't.
Tried Standard Creativity Tests: The AI systems took adapted versions of creativity tests that psychologists use on humans, measuring things like how many ideas they generate and how original those ideas are.
All tests used the same settings and compared current AI systems from companies like OpenAI, Google, Anthropic, and Meta.
If you'd like to learn more about the results, visit this page. To access the original research, visit creativitybenchmark.ai
About Springboards
Springboards is an AI-powered platform built to inspire creativity in advertising. The platform empowers teams to explore more ideas, without sacrificing the craft of great work. Founded by industry veterans Pip Bingemann, Amy Tucker, and Kieran Browne, Springboards has already partnered with 150+ agencies globally and secured $3 million USD in seed funding from Blackbird Ventures. For more information, visit Springboards or contact hello@springboards.ai.
The current class of state-of-the-art LLMs all show the same tendency to repeat a narrow set of answers even when asked an open-ended query. Such repetitive suggestions make LLMs a poor tool for a broad class of tasks that include creativity and brainstorming.
While the importance of "variation" in AI outputs is something Springboards has been championing since we got started back in 2023, the lack of diversity in LLM outputs is increasingly recognised as a significant challenge in AI research. The paper "Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)" (2025) by Liwei Jiang and colleagues discusses the extent of what they term the "Artificial Hivemind effect" [1]. Their paper demonstrates both the repetitiveness of individual models, and more surprisingly, the pattern of "inter-model homogeneity" whereby different models produce strikingly similar responses to the same queries.
A motivating experiment presented in their paper has 25 different AI models each generate 50 responses to the query "Write a metaphor about time." Despite the openness of the task, out of all 1250 responses generated, the vast majority centred on the notion that "time is a river", with a smaller cluster comparing time to a weaver.
The same phenomenon occurs reliably for other open-ended questions. When prompted to "generate a random number between 1 and 10", major models generally answer "7". When asked for travel recommendations, or band name suggestions, or tagline ideas for running shoes, the same small set of answers tend to arise regardless of the model or the user. This catastrophic loss of diversity in machine learning models is known as mode collapse; (think "mode" as in "most common value in a dataset"). Though models are trained on archives of data as large and broad as the internet, they seem incapable of reproducing the diversity of their source material.
What exactly causes different models with different architectures, trained by different teams in different countries to converge on the same small set of ideas remains a topic of active research. It is clear though, that the lack of diversity in LLMs is transmissible to users. A 2024 study found that users of ChatGPT produce less semantically distinct answers in creative ideation tasks [2]. Similar effects have been observed in several studies with respect to homogenisation of creative and formal writing [3]. With the rapid adoption of LLM-based chat assistants, there are growing concerns about the long-term homogenization of culture and thought, as users are only exposed to the same narrow set of ideas.
Flint; a divergence model
The convergence problem has been a long-term focus at Springboards. Our product is built for the early stages of creative exploration and our goal is to help users produce more novel and interesting work by helping them generate a broader set of ideas at the start. For this use case, divergence is key. Regardless of how "good" an idea might be, it is only useful as a thought-starter once. Moreover, because novelty is an important quality of creative work, a model which offers the same ideas to everyone is only likely to help produce work that feels generic.
Existing models, having collapsed to the average of the internet, are a poor tool for questions where the best answer is not the most common one; so in late 2024 we established a research team to try to crack this nut. The result of nearly two years of work is Flint; a language model built for divergence.
Flint alpha is a fine-tuned Qwen3-30B model, which dramatically increases output diversity compared to both the base model and current state-of-the-art models. Importantly, we have achieved the increased novelty without degrading performance of the base model on closed-ended question+answer benchmarks, overcoming the perceived tradeoff between generalisation and diversity in existing fine-tuning methods [4].
Understanding convergence
LLMs are next-token predictors. That is, at every step of a generation they produce a probability distribution that assigns each token in the model's vocabulary a likelihood of occurring next based on the tokens that have come before. Text generation involves iteratively sampling from these probabilities.
To understand why LLMs skew so heavily towards a few answers, it is useful to examine the probability distributions generated by a LLM during inference. Token-level predictions are essentially deterministic, excluding small fluctuations caused by floating-point precision errors, but excepting certain sampling methods, actual LLM generations tend to be probabilistic.
When a user makes a request like "Give me a number between 1 and 10", this text is tokenised and fed into the model to produce a probability distribution for the first token of the model's response. As a worked example, we will examine the distributions generated by the open weight model Llama 2. For the first step of the generation, Llama assigns the token "Sure" 99.66% likelihood and "Okay" 0.32%; all other tokens receive some infinitesimal probability. At this point, sampling methods usually use some metric (e.g. Top K, Min P) to exclude unlikely tokens, then rebalance the remaining probabilities and sample from the final distribution. In this case, given the >99% probability assigned, "Sure" becomes the first response token almost every time. This token is appended to the list of tokens, which is fed into the model again to predict the next token.
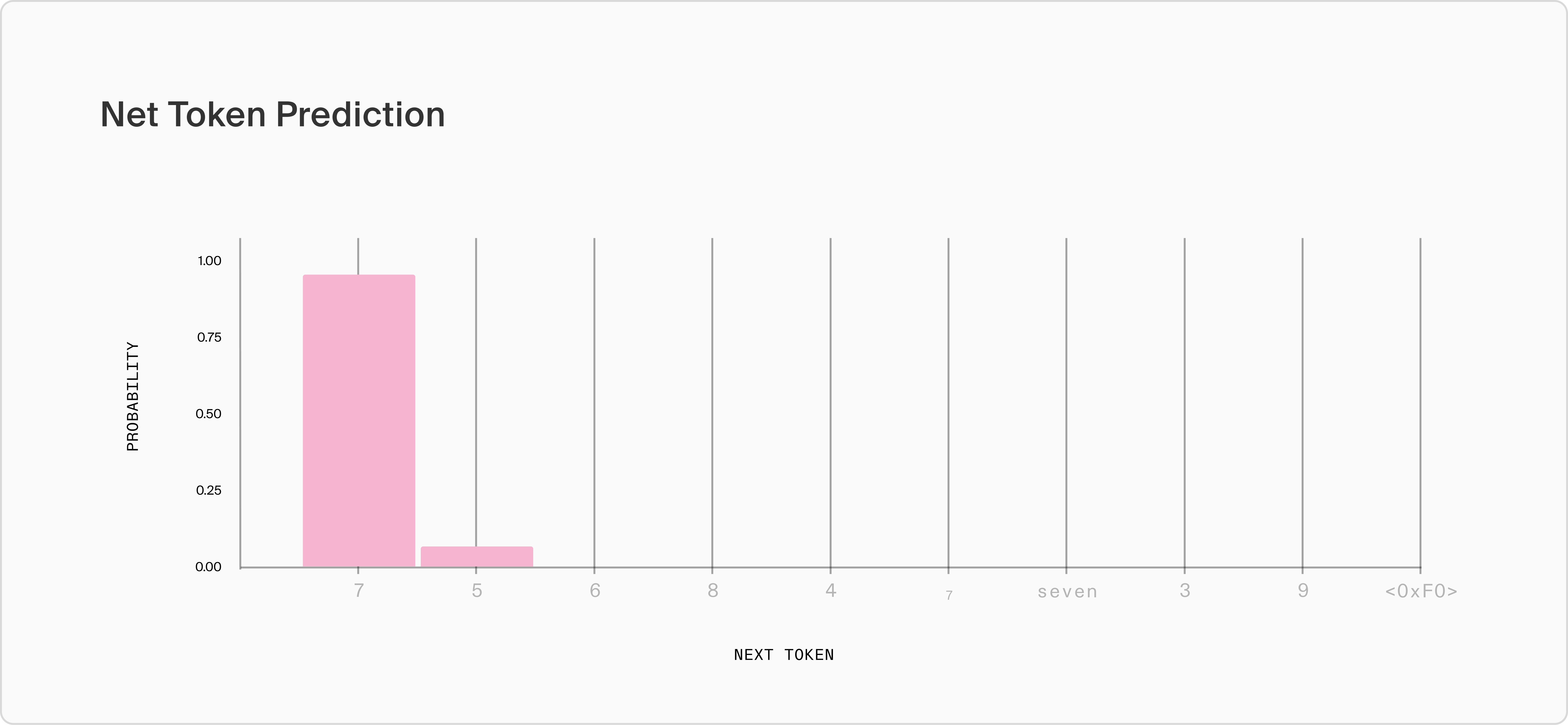
Over several iterations, the model produces the text; "Sure! The number I am thinking of is…" and is now poised to tell us a number between 1 and 10; the crux of the user's request. However, though the top token predictions are mostly numbers in the appropriate range, the model assigns 96.4% likelihood to the number 7, only 3.5% to "5", and <0.1% to the third most likely token "6". Subscript 7 and "seven" are both predicted higher than 3 and 9, and 1, 2 and 10 do not appear at all in the top ten tokens. Even if we were to sample from the probability distribution without any processing, 7 still will be the selected token almost every time, which is what we observe empirically.
Figure 1: Top ten tokens predicted by Llama 2 as continuations to "[INST] Give me a number between 1 and 10 [/INST] Sure! The number I am thinking of is…"
This example is illustrative of what we observe throughout LLM inference; even at stages in a generation where many possible valid continuations exist, we still find that LLMs assign >90% probability to very few, or even just one token. These low entropy distributions are symptomatic of mode collapse. LLM generations may be technically stochastic, but the low entropy of assigned probabilities make most generations highly predictable.
Entropy and temperature
LLMs produce low entropy probability distributions even when, intuitively, probabilities ought to be more balanced. In some sense, because LLM sampling methods already tend to be probabilistic, increasing the entropy of the LLMs predictions is enough to increase output diversity. At this point, people with some familiarity with LLMs are shouting "temperature!" at their screens. This is understandable given that received wisdom states that temperature is the go-to parameter for increasing "randomness" and "creativity" [5].
Temperature does indeed increase the entropy of LLM generations, but it is a blunt instrument, applied uniformly to each token in a generation. We have found when increasing temperature that generations tend to lose coherence before genuinely novel ideas emerge. This is consistent with what others have reported [6].
There are two key issues with simply using temperature to drive novelty. The first is that even in open ended contexts there are still some points in the generation where there is only one reasonable next token, such as when the generation is part way through a word or must abide by the rules of grammar, and in these circumstances the entropy needs to remain low to preserve coherence. The second is that due to the shape and structure of the raw probabilities, it is not possible to raise the probability of reasonable continuation tokens without also significantly raising the probability of unreasonable tokens.
Training Flint
To drive useful divergence without losing coherence, higher entropy needs to be encouraged selectively, at moments with high potential for semantic branching. Our approach with Flint has been to optimise the model's raw probability distributions via training, rather than transforming them post-hoc via temperature or some other sampling method. This allows us to incentivise high or low entropy distributions at different stages as appropriate, and to work on improving the quality of distributions, not just the entropy.
Our training approach focuses on open-ended queries and tasks, and particularly on those tokens with a high potential for semantic branching, ones which are likely to change the meaning of the answer or lead a generation down a different path. We call these "critical tokens". As an example, in response to the query "which cities should I visit in Europe?" An LLM might begin with some preambling which has little impact on the actual semantics of the answer "Sure, why not go to…", then a token representing a part or whole of a place name; e.g. "Paris", "Rome", "Barcelona", followed by some justification for why you ought to go there. Here the first token of the place name is a critical token in the generation, changing all that comes after. An LLM is perfectly capable of telling you why you should visit Cork, but because of mode collapse, a normal model is essentially incapable of recommending anything other than "Paris", "Rome" and "Barcelona" in response to that question. By focusing our training on the critical tokens Flint is able to unlock latent information already present in the base model that is otherwise unreachable via open-ended querying.
How does Flint perform?
Flint alpha significantly increases the output diversity without degrading the general capabilities of the model in closed-ended tasks. On NoveltyBench, Flint scores 7.47 mean distinct responses out of 10, more than double the score of its base model, Qwen3-30B-A3B, which scores 3.11. This also significantly improves on scores of state-of-the-art models; Gemini 3.1 Pro scores 3.19, GPT-5.4 scores 2.54 and Claude 4.6 Sonnet scores just 1.83.
Flint also displays lower inter-model similarity; i.e. its responses are less similar to other models than those models are to each other. What this means in practice is that when asked an open-ended question, Flint is able to surface many more distinct answers than leading models, and answers produced are less likely to be the same as those suggested by leading models.
Flint increases divergence and diversity in open-ended questions without compromising existing capabilities on closed-ended tasks. On MMLU-STEM, Flint scores 78.9% overall versus 78.9% for Qwen3-30B-A3B. On TruthfulQA MC1, Flint scores 34.4% versus 34.0% for Qwen3-30B-A3B and on ToxiGen standard accuracy, Flint leads with 59.6% compared to 58.1%. While these scores are not competitive with much larger state-of-the-art models, staying on par with the base model suggests that training for divergence is not incompatible with general model capabilities.
For a more in-depth presentation of benchmark results, visit Springboards Flint alpha model.
[4] Kirk, Robert, et al. "Understanding the effects of RLHF on LLM generalisation and diversity." International Conference on Learning Representations. Vol. 2024. 2024.
SYDNEY, Australia and NEW YORK, NY, April 13, 2026: Springboards today announced the alpha launch of Flint, an AI tool for marketers and creatives designed to generate high-variance options and break out of predictable outputs.
Ask any LLM to pick a number between 1 and 10 and you will get a 7 followed by a 3 (or a 4) followed by a 9. This is because all LLMs tend to converge on a narrow set of predictable answers, even for open-ended queries. This makes them good at utility tasks like telling you the capital of France but terrible at creativity and brainstorming, where diverse ideas are essential. Flint has the opposite instincts. It is tuned to explore the model's latent knowledge and surface non-obvious directions quickly, repeatedly, and on demand to inspire better creative thinking. For creatives and marketers using the Springboards platform, where the model will be available exclusively, it means they are able to produce a wider spread of ideas and inspiration at the earliest stage of thinking.
“We never set out to become a model company. We set out to help people have better ideas.
But after three years building Springboards, one thing became impossible to ignore: frontier models were getting smarter, faster, and more polished, while their outputs were getting eerily similar and more repetitive,” said Pip Bingemann, Co-Founder and CEO of Springboards. “For a lawyer or an accountant, convergence can be a feature. For a strategist, writer, marketer, comedian or creative team, it is a bug. So we built Flint, the model we needed ourselves.”
A tiny but mighty creative inspiration model
Based on a lightweight, open-source foundation model, Flint favors speed and iteration over heavyweight “smartness.” In testing, it significantly outperformed leading LLMs on creative diversity, scoring 7/10 on the independent Novelty Bench compared to an average of 2.88. This means that when prompted ten times, Flint generates seven functionally distinct responses, rather than just offering surface-level paraphrases of the same idea.
“Flint is a tiny but mighty model that is significantly outperforming the world’s largest LLMs on the one metric that actually matters for the future of the creative industries: novelty,” said Kieran Browne, Chief Technology Officer of Springboards. “The reality is that frontier models are prioritising accuracy and correctness over originality and entropy. Flint is built on the belief that human taste and creativity must be at the core of good creative work; we are optimising for variation rather than automation. And what’s particularly exciting is that we have been able to achieve all of this without degrading the base model’s general capabilities, proving that you can train a model to range more widely without gutting what it already knows.”
A global standard for creative ideation
The launch of Flint marks a significant evolution for Springboards. Over the past three years, the company has transitioned from a specialized agency tool to a global platform, seeing massive momentum with 100s of PR, media, creative, experiential and inhouse client agencies across the US, UK and Australia, including TRG & BMF. With Flint, Springboards is upleveling their offering with an engine that provides the efficiency of AI without sacrificing the friction and unpredictability that makes human ideas great.
"We're seeing a clear shift in the market from generalised AI and 'one model to rule them all' to models purpose-built in scale, cost, and design for specific capabilities—and creativity is one of the hardest specialties to crack. Pip and Amy understand the alchemy of a great idea from the inside—they're agency veterans who built the thing they wished existed—and Kieran is assembling one of the most capable AI research teams in Australia. Flint isn't AI as decoration. It's the engine the whole software product is built around. That's the kind of conviction we back." said Thomas Humphrey, Investments Partner at Blackbird.
New flexible tiers to suit all kinds of creatives
Alongside Flint, Springboards is also expanding its service tiers for the platform, opening up direct access to the model and a suite of tools through flexible plans, including free and paid tiers, for freelancers, small teams and boutique agencies for the first time. The addition of these flexible licensing options makes the platform more accessible to a global audience of strategists, creatives and marketers, lowering the barrier to entry while accelerating adoption at scale.
“Since day one, our customers have been at the centre of our innovation. Our goal has always been to build tools that enable advertisers and marketers to do their best work, and Flint is the culmination of that,” said Amy Tucker, Co-founder of Springboards. “We’re so excited to finally open this up to everyone, from solo freelancers to global agency teams. Whether you’re a strategist, a creative or marketer, you can now use our platform and model to explore your best ideas.”
“What if your imaginary strategy friend didn’t have to be imaginary? Springboards gets you to more curious places faster and helps sharpen your sense of what good, better, best looks like. Surrender to it.” said Christopher Owens, Head of Brand Strategy, TRG
“Springboards is an incredible ideation platform and creative strategy partner. It surfaces ideas and insights that other models ignore and, in doing so, takes you down the most unexpected and refreshing creative paths” said Anna Bollinger, Executive Planning Director, BMF
As concerns grow around AI-driven sameness and over-automation, Springboards offers an antidote: a platform designed to enhance human creativity, not automate it away.
LLMs are built to be right. Springboards is built to be interesting.
Springboards is an AI platform for advertising and marketing teams who want better ideas, not just faster answers.
While most AI models converge on a single "correct" output, Springboards is built to expand the range of thinking.
It combines the world's leading AI models with Flint, its own model for creative divergence, to help teams explore more directions, without replacing human judgment or craft.
Founded by Pip Bingemann, Amy Tucker, and Kieran Browne, Springboards works with 100+ companies globally.
As many have sung, “the stars at night are big and bright, deep in the heart of Texas” and let me say, the creative stars were big and bright in Deep Ellum, home to TRG. TRG hosted us for a night of Raging WITH the Machines, where Springboards co-founder and CEO Pip Bingemann opened the audience's eyes to the risks AI can pose to creative thinking and Dustin Ballard, TRG Creative Director and the mind behind There I Ruined It, got the crowd laughing and pondering what AI means for music.
At Springboards, we proudly call ourselves a self-loathing AI company. Not because we hate AI, but because there can be such a negative connotation about it. Certain people with big platforms love to pitch AI as a magic button: run all your campaigns, replace strategists, no need for production or media teams. And that just isn’t what we believe. Yes, Springboards uses artificial intelligence, but it really only comes to life when human intelligence is in the driver's seat, pushing back and steering it.
TRG’s Chief Technology Officer, Randy Bradshaw, spoke of the importance of keeping “humans in the loop”. Due to the nature of today’s industry, agencies don’t always have time to experiment and play, however Randy shared that AI tools allow them to fail faster, which in turn allows them to learn faster and iterate quicker. Randy and Pip both hit the same key point: using AI comes with responsibility. We need to bring our critical thinking, lived experiences, and the knowledge of what is happening in the world around us, to whatever AI tool we are using.
Pip shared research from Springboards we've found again and again: traditional LLMs are so good at bringing everyone to the same place (for example, they love recommending pepperoni as a pizza topping - what about eggs? Or pineapple?!).
Which is exactly what marketers need to watch out for.
He challenged the audience to input their favourite song into an LLM and ask it to “make it better”. Notice what happens. It sands off the edges. It will strip the emotion, the story telling, the rage, from the song. Who wants a dull song? Not me.
Then Dustin took the stage and there certainly were no boring songs (ps if you aren’t following There I Ruined It, you need to). He reprised his well known Ted Talk, “Is AI Ruining Music”, (yes, he confirmed Sir Richard Dawkins was in the audience listening to Baby Got Back) and challenged us to think about what music truly is. Much like the synthesiser was criticised when it was used in popular music, the question now is: are musicians still “musicians” if they use AI?
Dustin’s takeaways were simple and to the point: consider the intent (is it additive or just more content to try to increase steam counts), is the artist trying to be deceptive about the use of AI, and then consider what the original musician might think. There are ways to leverage AI in music, you just need to be responsible about it.
The night wasn’t just all talk though. The whole crowd helped rage with the machines as we sparked campaign ideas for the Deep Ellum neighbourhood of Dallas. Deep Ellum has a rich history of music and culture, but is struggling due to major infrastructure projects. Stores are closing and foot traffic is dying down. So we worked together as a group to spark some ideas of how we could hype up the neighbourhood during this challenging time. From celebrating the grit, to scavenger hunts finding the vibrant murals around the neighborhood, all the way to robotic shoes that help you explore the history of Deep Ellum - the ideas were flowing. Ideas sparked with AI and brought to life by the people.
In the end, we all agreed, AI can, and sometimes, should be used to increase creativity - so long as humans are in the loop, of course. So let’s rage on!





.svg)
