How we built Flint: training AI for higher entropy
Ask any AI for creative ideas and you'll get the same handful of answers. Every time. Across every model. Researchers call this the Artificial Hivemind effect. Springboards built Flint to fix it.
For a high-level overview of the model, visit Flint alpha model.
The convergence problem
The current class of state-of-the-art LLMs all show the same tendency to repeat a narrow set of answers even when asked an open-ended query. Such repetitive suggestions make LLMs a poor tool for a broad class of tasks that include creativity and brainstorming.
While the importance of "variation" in AI outputs is something Springboards has been championing since we got started back in 2023, the lack of diversity in LLM outputs is increasingly recognised as a significant challenge in AI research. The paper "Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)" (2025) by Liwei Jiang and colleagues discusses the extent of what they term the "Artificial Hivemind effect" [1]. Their paper demonstrates both the repetitiveness of individual models, and more surprisingly, the pattern of "inter-model homogeneity" whereby different models produce strikingly similar responses to the same queries.
A motivating experiment presented in their paper has 25 different AI models each generate 50 responses to the query "Write a metaphor about time." Despite the openness of the task, out of all 1250 responses generated, the vast majority centred on the notion that "time is a river", with a smaller cluster comparing time to a weaver.
The same phenomenon occurs reliably for other open-ended questions. When prompted to "generate a random number between 1 and 10", major models generally answer "7". When asked for travel recommendations, or band name suggestions, or tagline ideas for running shoes, the same small set of answers tend to arise regardless of the model or the user. This catastrophic loss of diversity in machine learning models is known as mode collapse; (think "mode" as in "most common value in a dataset"). Though models are trained on archives of data as large and broad as the internet, they seem incapable of reproducing the diversity of their source material.
What exactly causes different models with different architectures, trained by different teams in different countries to converge on the same small set of ideas remains a topic of active research. It is clear though, that the lack of diversity in LLMs is transmissible to users. A 2024 study found that users of ChatGPT produce less semantically distinct answers in creative ideation tasks [2]. Similar effects have been observed in several studies with respect to homogenisation of creative and formal writing [3]. With the rapid adoption of LLM-based chat assistants, there are growing concerns about the long-term homogenization of culture and thought, as users are only exposed to the same narrow set of ideas.
Flint; a divergence model
The convergence problem has been a long-term focus at Springboards. Our product is built for the early stages of creative exploration and our goal is to help users produce more novel and interesting work by helping them generate a broader set of ideas at the start. For this use case, divergence is key. Regardless of how "good" an idea might be, it is only useful as a thought-starter once. Moreover, because novelty is an important quality of creative work, a model which offers the same ideas to everyone is only likely to help produce work that feels generic.
Existing models, having collapsed to the average of the internet, are a poor tool for questions where the best answer is not the most common one; so in late 2024 we established a research team to try to crack this nut. The result of nearly two years of work is Flint; a language model built for divergence.
Flint alpha is a fine-tuned Qwen3-30B model, which dramatically increases output diversity compared to both the base model and current state-of-the-art models. Importantly, we have achieved the increased novelty without degrading performance of the base model on closed-ended question+answer benchmarks, overcoming the perceived tradeoff between generalisation and diversity in existing fine-tuning methods [4].
Understanding convergence
LLMs are next-token predictors. That is, at every step of a generation they produce a probability distribution that assigns each token in the model's vocabulary a likelihood of occurring next based on the tokens that have come before. Text generation involves iteratively sampling from these probabilities.
To understand why LLMs skew so heavily towards a few answers, it is useful to examine the probability distributions generated by a LLM during inference. Token-level predictions are essentially deterministic, excluding small fluctuations caused by floating-point precision errors, but excepting certain sampling methods, actual LLM generations tend to be probabilistic.
When a user makes a request like "Give me a number between 1 and 10", this text is tokenised and fed into the model to produce a probability distribution for the first token of the model's response. As a worked example, we will examine the distributions generated by the open weight model Llama 2. For the first step of the generation, Llama assigns the token "Sure" 99.66% likelihood and "Okay" 0.32%; all other tokens receive some infinitesimal probability. At this point, sampling methods usually use some metric (e.g. Top K, Min P) to exclude unlikely tokens, then rebalance the remaining probabilities and sample from the final distribution. In this case, given the >99% probability assigned, "Sure" becomes the first response token almost every time. This token is appended to the list of tokens, which is fed into the model again to predict the next token.
Over several iterations, the model produces the text; "Sure! The number I am thinking of is…" and is now poised to tell us a number between 1 and 10; the crux of the user's request. However, though the top token predictions are mostly numbers in the appropriate range, the model assigns 96.4% likelihood to the number 7, only 3.5% to "5", and <0.1% to the third most likely token "6". Subscript 7 and "seven" are both predicted higher than 3 and 9, and 1, 2 and 10 do not appear at all in the top ten tokens. Even if we were to sample from the probability distribution without any processing, 7 still will be the selected token almost every time, which is what we observe empirically.
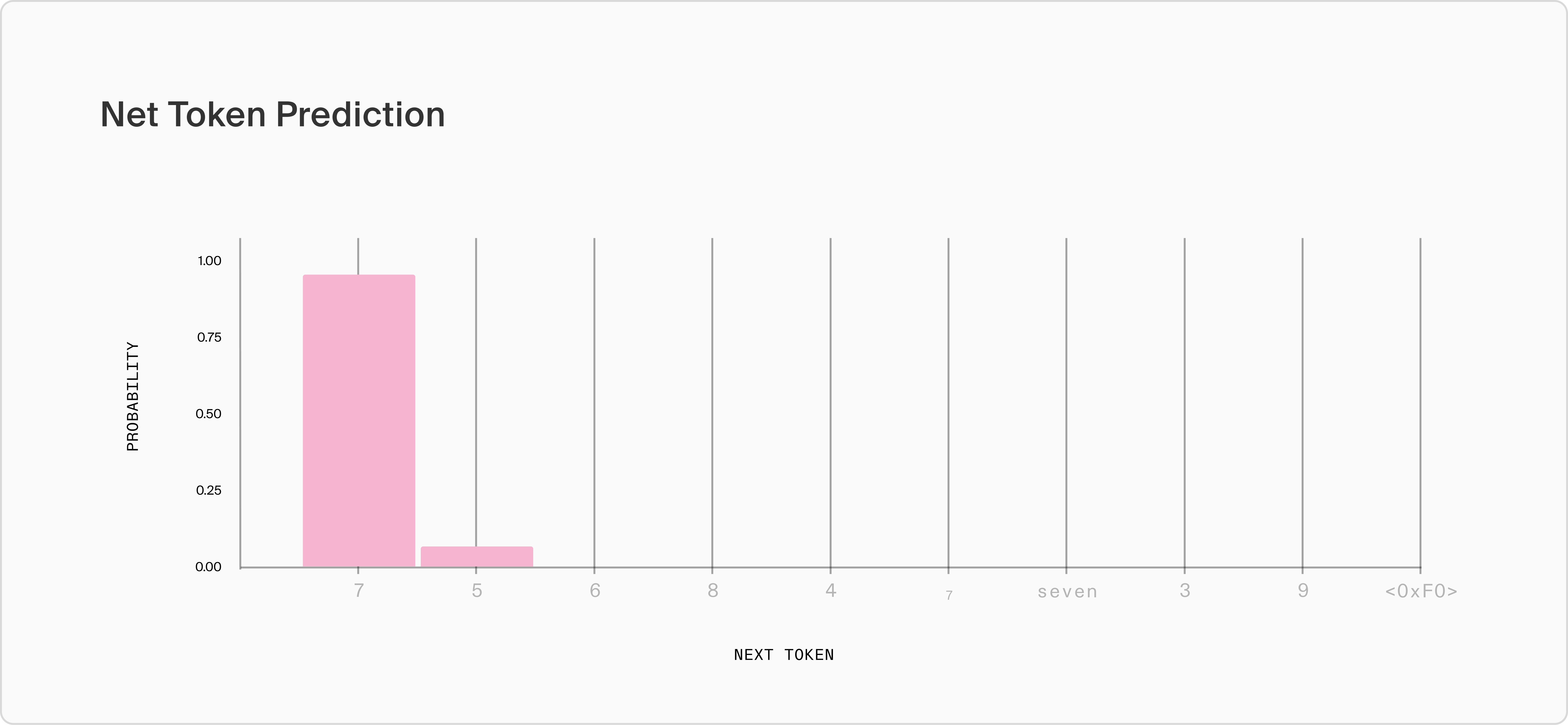
This example is illustrative of what we observe throughout LLM inference; even at stages in a generation where many possible valid continuations exist, we still find that LLMs assign >90% probability to very few, or even just one token. These low entropy distributions are symptomatic of mode collapse. LLM generations may be technically stochastic, but the low entropy of assigned probabilities make most generations highly predictable.
Entropy and temperature
LLMs produce low entropy probability distributions even when, intuitively, probabilities ought to be more balanced. In some sense, because LLM sampling methods already tend to be probabilistic, increasing the entropy of the LLMs predictions is enough to increase output diversity. At this point, people with some familiarity with LLMs are shouting "temperature!" at their screens. This is understandable given that received wisdom states that temperature is the go-to parameter for increasing "randomness" and "creativity" [5].
Temperature does indeed increase the entropy of LLM generations, but it is a blunt instrument, applied uniformly to each token in a generation. We have found when increasing temperature that generations tend to lose coherence before genuinely novel ideas emerge. This is consistent with what others have reported [6].
There are two key issues with simply using temperature to drive novelty. The first is that even in open ended contexts there are still some points in the generation where there is only one reasonable next token, such as when the generation is part way through a word or must abide by the rules of grammar, and in these circumstances the entropy needs to remain low to preserve coherence. The second is that due to the shape and structure of the raw probabilities, it is not possible to raise the probability of reasonable continuation tokens without also significantly raising the probability of unreasonable tokens.
Training Flint
To drive useful divergence without losing coherence, higher entropy needs to be encouraged selectively, at moments with high potential for semantic branching. Our approach with Flint has been to optimise the model's raw probability distributions via training, rather than transforming them post-hoc via temperature or some other sampling method. This allows us to incentivise high or low entropy distributions at different stages as appropriate, and to work on improving the quality of distributions, not just the entropy.
Our training approach focuses on open-ended queries and tasks, and particularly on those tokens with a high potential for semantic branching, ones which are likely to change the meaning of the answer or lead a generation down a different path. We call these "critical tokens". As an example, in response to the query "which cities should I visit in Europe?" An LLM might begin with some preambling which has little impact on the actual semantics of the answer "Sure, why not go to…", then a token representing a part or whole of a place name; e.g. "Paris", "Rome", "Barcelona", followed by some justification for why you ought to go there. Here the first token of the place name is a critical token in the generation, changing all that comes after. An LLM is perfectly capable of telling you why you should visit Cork, but because of mode collapse, a normal model is essentially incapable of recommending anything other than "Paris", "Rome" and "Barcelona" in response to that question. By focusing our training on the critical tokens Flint is able to unlock latent information already present in the base model that is otherwise unreachable via open-ended querying.
How does Flint perform?
Flint alpha significantly increases the output diversity without degrading the general capabilities of the model in closed-ended tasks. On NoveltyBench, Flint scores 7.47 mean distinct responses out of 10, more than double the score of its base model, Qwen3-30B-A3B, which scores 3.11. This also significantly improves on scores of state-of-the-art models; Gemini 3.1 Pro scores 3.19, GPT-5.4 scores 2.54 and Claude 4.6 Sonnet scores just 1.83.
Flint also displays lower inter-model similarity; i.e. its responses are less similar to other models than those models are to each other. What this means in practice is that when asked an open-ended question, Flint is able to surface many more distinct answers than leading models, and answers produced are less likely to be the same as those suggested by leading models.
Flint increases divergence and diversity in open-ended questions without compromising existing capabilities on closed-ended tasks. On MMLU-STEM, Flint scores 78.9% overall versus 78.9% for Qwen3-30B-A3B. On TruthfulQA MC1, Flint scores 34.4% versus 34.0% for Qwen3-30B-A3B and on ToxiGen standard accuracy, Flint leads with 59.6% compared to 58.1%. While these scores are not competitive with much larger state-of-the-art models, staying on par with the base model suggests that training for divergence is not incompatible with general model capabilities.
For a more in-depth presentation of benchmark results, visit Springboards Flint alpha model.
Footnotes
[4] Kirk, Robert, et al. "Understanding the effects of RLHF on LLM generalisation and diversity." International Conference on Learning Representations. Vol. 2024. 2024.
[5] OpenAI. "Best practices for prompt engineering with the OpenAI API."




.svg)
